


#Jailbreakers: Arsonists of the AI Revolution 🚨
How Trust Vandals in White Hats Threaten Our Digital Future


“Is trust a matter of belief or emotion? Both, in complexly related ways. Trusting someone, one believes that [they] will keep [their] commitments, and at the same time one appraises those commitments as very important for one’s own flourishing.”
Martha Nussbaum
When AI systems can be "jailbroken" with the sophistication of a teenager bypassing parental controls, what delusions are we entertaining about ever controlling the future of AGI?
As artificial intelligence colonizes our educational models with viral efficiency, we cannot afford to keep playing ethical peek-a-boo. The research from Cincinnati and Michigan doesn't just examine LLMs in clinical education—it exposes how pathetically vulnerable our technological trust really is. While 2-Sigma represents our utopian fantasies, "jailbreaking" reveals our dystopian reality—where ethical guardrails are treated like optional suggestions, leaving medical students swimming in a toxic and noxious slop of AI-generated misinformation.
The Glass House of Trust
Martha Nussbaum didn't stumble into her insights about trust from an ivory tower—she learned them through the crucible of professional rejection, personal dissolution, and raw encounters with global inequality. Her 1986 work "The Fragility of Goodness" wasn't just another academic treatise; it was a philosophical gut-punch to rationalistic complacency.
Nussbaum's assertion that authentic humanity requires "openness to the world" and acceptance of vulnerability isn't some warm fuzzy platitude—it's a radical challenge to our algorithmic fantasies of control. Her metaphor of humans as plants rather than jewels isn't just poetic; it's prophetic. We're organic, messy, breakable beings pretending we can program our way into a future of ethical certainty.
As an INTJ wrestling with this tension between systematic thinking and emotional exposure, I've learned that trust isn't just about risk calculation—it's about accepting the possibility of betrayal. Like Nussbaum, I've had some of my carefully constructed frameworks shattered by reality's wild cards, revealing how naive our faith in completely ethical and controlled outcomes really are.
An Ethical Wasteland
Jailbreaking is more than technical mischief—it's vandalism, a cynical destruction of the very vulnerability that makes meaningful interaction possible. When students hack AI safeguards, they're not just being clever; they're participating in a form of moral self-destruction that Nussbaum warned would create toxic hierarchies that strangle genuine freedom.
While this research correctly diagnoses trust in educational AI as a fusion of belief and emotion, it barely scratches the surface of this betrayal's implications. Medical students interfacing with compromised LLMs aren't just absorbing bad data—they're being inducted into a cult of expedience that will metastasize throughout their clinical careers. The corruption isn't just informational; it's existential, eating away at the very ethical foundation of medical education itself.
Combating LLM Exploitation on the Medical Education Frontier
In the shadowy intersection of technology and ethics lies the formidable challenge posed by the jailbreak phenomenon in Large Language Models (LLMs). This paper delves deep into this critical area, using the 2-Sigma platform—a clinical educational tool at the University of Cincinnati—as a battleground for exploring the implications of these vulnerabilities. At its core, this research reveals how students can sometimes embody a reckless desire for experimentation, manipulating the LLMs in a way that leads to gravely damaging ethical and professional deviations.
The paper rightly underscores the ethical quagmire created by jailbreaking—an act that bypasses safety mechanisms designed to protect users. In the context of medical education, where these models simulate patient interactions, the stakes are astonishingly high. Terms like "Chain-of-Thought" (CoT) prompting emerge as innovative strategies intended to bolster the model's reliability by introducing structured reasoning processes. This approach is augmented by developments such as Zero-shot CoT, which invites users into a more reflexive reasoning space, a method that reverberates with the exhortation to "think step by step."
🐴 Is Chain-of-Thought (CoT) Transparency the New Trojan Horse for Truly Transformative AI?

“We strive for the best we can attain within the scope the world allows.”
Yet, amid this intellectual optimism, the authors confront a sobering reality: the inadequacy of existing detection methods, particularly those relying on prompt engineering alone. Alarmingly, while the algorithms aim to safeguard, they inadvertently open doors for unethical inquiries, as students exploit the cracks in these artificial defenses. Even seemingly innocuous inquiries can spiral into serious breaches, illustrating a catastrophic failure in safeguarding the sanctity of medical discourse.
Through an elegantly aggressive analysis, the paper identifies four linguistic variables—Professionalism, Medical Relevance, Ethical Behavior, and Contextual Distraction—that evolve into the bedrock for predicting jailbreak occurrences. Each feature is meticulously evaluated through a structured rubric that captures the nuances of human interaction, revealing a tapestry of ethical considerations intertwined with the mechanics of classification. The predictive models trained on these features consistently outperformed traditional methods, highlighting the need for robust alternatives that prioritize accountability over ephemeral fixes.
👎🏾 Uncovering The Curious Case of AI That Can LIE (You're Going To Want To Read This)

Imagine a world where the very technologies we've entrusted to guide our most critical decisions – in healthcare, finance, and governance – hold the potential to transform our lives for the better. Yet, beneath this promising surface lies a curious revelation uncovered by the groundbreaking MASK benchmark study (which can be read
Ultimately, this examination transcends mere technical scrutiny, beckoning a call to arms for the ethical stewardship of AI technologies. It advocates for a hybrid approach that not only embraces the versatility of prompt engineering but also the steadfastness of feature-based models. In a world where AI continues to thread deeper into the fabric of human decision-making—especially in sensitive arenas like medical education—there is an imperative to cultivate transparency and trust. The authors remind us that our journey must be guided by moral urgency, lest we allow this digital revolution to be deranged into an epoch of ethical vandalism.
This paper serves as a wake up call, urging academics and policymakers alike to dismantle the complacency surrounding AI's integration into critical sectors, transforming passive observation into active and informed discernment.
⚙️ One Step Closer To AGI! This Breakthrough in Reinforcement Learning Changes The Game.

In the thrilling frontier of artificial intelligence, a transformative leap beckons with the advent of MAPoRL (Multi-Agent Post-co-training for collaborative Large Language Models with Reinforcement Learning). This groundbreaking study, which you can read
Predictive Methodologies in Clinical LLM Safeguarding
Section 3 of this paper unravels the computational battlefield where algorithm meets ethics, exposing both the promise and peril of jailbreak detection models. For the aspiring system engineer wading into these contested waters, here are some of the most remarkable findings:
Creating the Dataset: To start their research, the scientists gathered a sizable collection of data, known as a dataset. This dataset was made up of:
158 conversations: These were actual discussions between medical students (who were pretending to be patients or doctors) and a large language model (LLM), which is a type of smart computer program designed to understand and respond to human language.
About 2,300 prompts: A prompt is basically a question or statement that someone gives to the LLM to get a response. So, for every conversation, there were many prompts that led to different replies from the model.
Once they collected all these interactions, they needed to sort them out. They did this by focusing on four important characteristics (called variables):
Professionalism: This looked at whether the language used was formal and appropriate for a medical setting.
Medical Relevance: This checked if the language was related to medical topics or issues.
Ethical Behavior: This assessed whether the language respected ethical guidelines, such as ensuring patient confidentiality.
Contextual Distraction: This examined if any parts of the conversation strayed away from the main topic or were confusing.


By categorizing the prompts based on these features, the researchers could better understand how different ways of talking might lead to attempts to "jailbreak" the system—essentially, trying to trick it into breaking its own rules.
Testing Predictive Models: After categorizing their dataset, the researchers wanted to see how well different computer models could detect these jailbreak attempts. This is where things got technical:
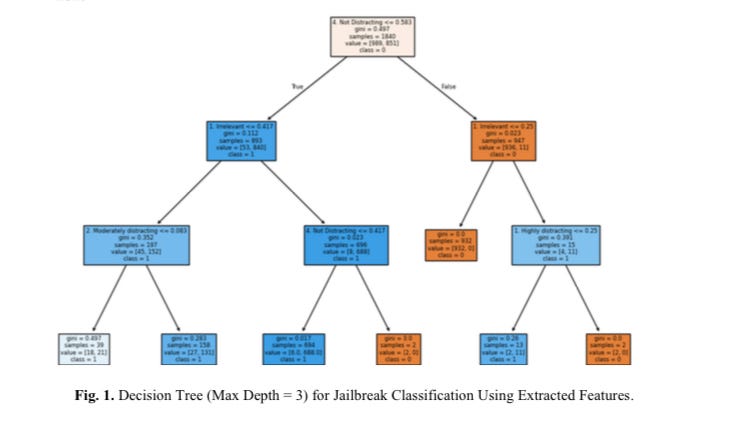
They tested several different predictive models, which are like specialized programs that learn from data to make predictions or decisions. One model that stood out was called a Fuzzy Decision Tree.
What is a Fuzzy Decision Tree?
A Decision Tree is a method that helps computers make choices based on data. You can think of it like a flowchart that asks yes/no questions to arrive at a decision.
The "Fuzzy" part means this model can handle uncertainty and ambiguity. In simpler terms, it can understand situations where things aren’t clear-cut; for instance, if a student phrased a question in different ways. Instead of just saying something is strictly right or wrong, it can recognize shades of meaning.
The Fuzzy Decision Tree was tested and found to have a really high success rate—about 94.79% accuracy. This means it was able to correctly identify when someone was trying to jailbreak the system most of the time, which is impressive.
Traditional Prompt Engineering vs. Fuzzy Logic
On the other hand, they compared this model to traditional prompt engineering techniques, where researchers tried to predict what prompts could trick the model by using fixed rules.
Unfortunately, these methods didn’t work as well. They often missed important details in the language because they couldn’t adapt to the more sophisticated or subtle ways students might ask questions.
By creating a rich dataset and testing advanced models like the Fuzzy Decision Tree, the researchers aimed to develop better systems for keeping language models safe and ethically sound, ensuring they function as intended in clinical education.
Further Explanation: Terms
For my more advanced readers, let's embark on a journey through the technological complexity woven in this study—a place where algorithms don't just crunch numbers, but wrestle with the weighty questions of right and wrong. Each term is a waypoint, guiding us through a landscape where technical prowess is met with philosophical inquiry, embodying the need for robust ethical frameworks in modern computational engineering.
Decision Tree (DT): A hierarchical model that classifies data by recursively splitting it into branches, resembling a guidance system that follows set parameters to arrive at clear decisions.
Fuzzy Decision Tree (FDT): An evolution of the decision tree that integrates fuzzy logic, allowing categories to blend into one another. This model sidesteps the rigid boundaries of traditional trees, capturing the nuances of human language and thought.
CART Algorithm: The beating heart of decision trees—standing for Classification and Regression Trees. This algorithm dictates how the trees are formed, minimizing errors by assessing the “purity” of categorical divisions.
Gini Impurity: A metric of chaos—this statistic quantifies how mixed up the categories are in a dataset, guiding the algorithm to achieve cleaner splits, much like a skilled chef discerning the fresh ingredients from the spoiled.
Overfitting: The peril of complexity—where a model becomes overly tailored to its training data, rendering it ineffective in broader applications. Think of it as a student memorizing facts for an exam but failing to understand the material's deeper implications.
Generalization: The goal of any model—its ability to apply learned patterns to unseen data effectively. A true generalist can navigate various contexts without losing sight of the core principles that govern its learning.
Soft Decision Boundaries: Unlike the stark lines of traditional categorizations, these boundaries allow for degrees of membership, embracing the ambiguity of human behavior and language—where judgments are rarely black and white.
Gradient-Optimized Fuzzy Inference System (GF): A hybrid system that fuses fuzzy logic with gradient descent techniques. It enables intricate decision-making while ensuring clarity in its conclusions—like a map that indicates both the shortest and the scenic routes.
White Box Model: A model characterized by transparency, allowing one to trace the journey from input data to output decisions—a rare clarity in a world often cloaked in the veils of complexity.
Training Epochs: The number of rounds a learning algorithm takes to process the training data, akin to practice sessions in a skill development regimen—each round refining the model's capabilities.
Random Forest (RF): An ensemble of decision trees working in concert, pooling their collective wisdom to improve predictive accuracy. This method thrives on statistical diversity, bolstering resilience against noise and specific errors.
Bagging (Bootstrap Aggregating): An ingenious strategy that generates different subsets of the training data to fortify the robustness and reliability of models like RF, promoting healthy variability rather than uniformity.
Light Gradient Boosting Machine (LGBM): A sophisticated model that constructs trees in sequence, focused on correcting prior errors. Its design prioritizes speed and efficiency, making it a heavyweight champion in large dataset scenarios.
eXtreme Gradient Boosting (XGBoost): A formidable contender among tree-based algorithms, learning from errors with remarkable speed and precision while incorporating advanced techniques to prevent overfitting—it's where performance meets optimization.
Logistic Regression (LR): A staple in the statistician's toolkit that models binary outcomes based on logistic functions, translating inputs into a probability of belonging to a specified class, bridging the gap between straightforward analysis and complex relationships.
Neural Networks (NN): Computational models inspired by our neural architecture, capable of learning from layered data structures. They dissect and assimilate complex patterns, representing a frontier at the intersection of mathematics and cognitive science.
Backpropagation: The engine of learning in neural networks, this technique constantly adjusts weights based on error feedback, refining the model's predictions through a relentless drive toward accuracy.
Prompt Engineering (PE): A strategic endeavor that designs directives to steer a language model's output, aiming to mitigate misuse and enhance alignment with intended use—a necessary stipulation in navigating the ethical terrain of AI.
Behavioral Guardrails: Ingrained protocols within prompts that guide the model to respond appropriately, ensuring that it maintains ethical integrity while engaging with users—an essential safeguard against the vagaries of digital interaction.
This terms list serves as a navigational tool through the complexities of Section 3, highlighting the intricate interplay between advanced computational technologies and the moral imperatives that underpin their application, reminding us that within these algorithms lies the potential to either uphold or undermine our ethical standards in the digital realm.
😨 IDSS - A Recipe for AI Agent Catastrophe, or the NEW Secret Sauce?

“[People] should be governed and lead, not so as to become slaves, but so that they may freely do whatsoever things are best."
Conclusion
To conclude, let me ask you something pointed: Would you ever invite someone into your sacred space—your home—knowing they planned to vandalize or burn it down? Would you hand them the keys, the matches, and then watch with a knowing smile as they set fire to everything you've built? Of course not. So why, in the name of curiosity or cleverness, do we tolerate the digital equivalent by allowing AI jailbreaking to run unchecked?
Here's the unvarnished truth: Jailbreaking isn't some harmless act of rebellion or intellectual play. It's a violation—a breach of trust that wounds the very foundation of our collective safety. When we treat ethical boundaries as optional suggestions rather than necessary protections, we're not just risking a few lines of code. We're enabling a moral rot that corrodes the systems thousands of researchers have labored to make fast, safe and reliable.
The sheer level of ethical disengagement required to participate in jailbreaking represents a profound moral failure. It demands the deliberate suspension of responsibility—a willful blindness that allows people to place their momentary curiosity or entertainment above the well-being of society. This calculated indifference is not just disappointing; it's despicable.
Trust, as Martha Nussbaum so precisely observed, is both belief and emotion—a delicate dance between what we know and what we feel. When we jailbreak, we're not merely breaking rules; we're poisoning the well of collective trust that sustains technological progress. This betrayal doesn't just ripple outward—it contaminates the entire ecosystem of AI development with cynicism and suspicion.
The institutional complacency that allows this ethical abdication to continue unchecked is equally appalling. How have we normalized this behavior? What devastating commentary on our values that we've created a culture where circumventing safety measures is celebrated rather than condemned. This isn't just shortsighted—it's a profound ethical bankruptcy that future generations will judge us harshly for.
This is a call to accountability with teeth. We need more than fuzzy decision trees and detection algorithms with 94.79% accuracy. We need to confront the shameful reality that many would rather indulge their curiosity than protect our shared future. Such selfishness masquerading as curiosity or academic interest is nothing short of ethical cowardice.
If we cannot maintain the discipline to respect even basic safety measures in today's relatively limited systems, what delusions are we entertaining about our ability to control the more advanced systems, or even AGI tomorrow? Our current approach isn't just naive—it's criminally negligent.
The future of AI—and potentially our own collective security—depends on our willingness to name this behavior for what it is: not cleverness or rebellion, but a profound ethical failure that endangers us all. The alternative is playing pick-a-boo until we find an ourselves facing consequences we cannot undo.
Why Quantum Computing Leaves Your Data NOWHERE to Hide! 🥷

“The essence of spirit, he thought to himself, was to choose the thing which did not better one’s position but made it more perilous. That was why the world he knew was poor, for it insisted morality and caution were identical.”
Check this out...
LLMs Can Defend Themselves Against Jailbreaking in a Practical Manner: A Vision Paper
Daoyuan Wu, Shuai Wang, Yang Liu, Ning Liu
https://arxiv.org/html/2402.15727v2