


DOES GE-Chat Deliver On ACCURACY & ACCOUNTABILITY As Promised? 🤔
A Graph Enhanced RAG Framework for Evidential Response Generation in LLMs


“Some things are believed because people feel as if they must be true, and in such cases an immense weight of evidence is necessary to dispel [or confirm] the belief.”
Bertrand Russell, The Impact of Science on Society
In a world increasingly dominated by artificial intelligence, a landmark report from Arizona State University and New Jersey Institute of Technology has ignited critical discourse. Released in May 2025 and authored by a team of experts, this report scrutinizes GE-Chat, a promising framework proposed to tackle persistent issues of accuracy and accountability in AI-generated responses. Yet, as we immerse ourselves in this examination, one must ask: does the emergence of GE-Chat truly signal a turning point in the fight against AI-generated misinformation? Or does it merely mask the same flawed underpinnings that haunt existing AI systems? In the face of rapid technological advancements, can we genuinely trust a system that claims to illuminate the truth, yet perpetuates the very hallucinations it purports to eliminate?
The report posits GE-Chat as a beacon of hope, asserting its potential to eradicate the inaccuracies plaguing contemporary AI models. However, this lofty ambition raises critical questions: Can a framework designed to unveil the reasoning behind AI outputs effectively dismantle the cognitive dissonance that so many users experience? Moreover, while it introduces sentence-level evidence tracing, does this innovation merely serve as a superficial bandage, leaving the deeper complexities of AI reasoning concealed beneath a veneer of transparency? It is easy to be seduced by the allure of such promises. Yet, if we can’t trust AI to articulate the rationale behind its responses, what faith can we place in its ability to guide our decisions? Is our reliance on these systems just a new form of intellectual laziness, outsourcing our thinking to machines that may be as confused as we are?
Moreover, the ethical conundrum extends into more profound territory: should we really allow machines—opaque and often inscrutable—to dictate the course of our lives? The implications of ceding significant decision-making power to systems like GE-Chat raise unsettling questions about agency and accountability. If a model can produce outputs based on reasoning that remains a “black box,” how can we rationalize the consequences of those outputs when lives are at stake? Are we inadvertently endorsing a culture of blind acceptance, prioritizing convenience over critical scrutiny? As we ponder the ramifications of entrusting AI with life-altering choices, we must confront the unsettling reality that perhaps the greatest risk lies not solely in the fallibility of these technologies, but in our willingness to unconditionally accept them without demanding the clarity and accountability they owe us.
Russell's Prescient Warning for the AI Age
Bertrand Russell's The Impact of Science on Society, published in 1952, examines how scientific advancements have profoundly influenced various aspects of human life. Writing during the aftermath of World War II and the dawn of the atomic age, Russell explored both the revolutionary benefits and inherent dangers of scientific progress. He traced the historical development of science from the Renaissance to the 20th century, noting how the Scientific Revolution replaced superstition and dogma with empirical evidence and reason.
Russell's analysis was remarkably balanced. While acknowledging science's positive contributions—improved healthcare, increased life expectancy, and greater access to knowledge—he remained deeply concerned about its potential misuses. He warned that technological advancements could increase state power through enhanced military capabilities and surveillance techniques, potentially enabling totalitarian regimes to leverage scientific progress for oppressive purposes.
The Prophetic Voice in the Digital Wilderness
Russell's concerns about mass psychology prove especially prescient in today's information ecosystem. He identified this field as "scientifically speaking, not a very advanced study" whose professors were primarily "advertisers, politicians, and, above all, dictators". This observation resonates powerfully in our era of AI-generated content and viral misinformation.
The philosopher envisioned mankind in "a race between human skill as to means and human folly as to ends," yet maintained an essential optimism that humanity would ultimately choose reason. This tension between technological capability and ethical responsibility forms the core challenge of our digital age, where AI systems like large language models can produce convincing yet potentially dangerous and misleading content.
From Russell to GE-Chat: The Struggle for Truth Continues
The GE-Chat framework represents a contemporary response to Russell's concerns, attempting to enhance the evidential integrity of AI-generated content through knowledge graphs and retrieval-augmented generation. By anchoring AI outputs in verifiable sources, such systems aim to reduce hallucinations and restore trust in digital information.
Yet the challenge remains formidable. Russell argued that science offers greater well-being than ever before, but only under specific conditions: prosperity must be dispersed, power diffused through global governance, population growth controlled, and war abolished. Similarly, our digital tools require careful governance and ethical frameworks to ensure they serve human flourishing rather than undermine it.
Russell's dual vision—optimistic about science's potential yet clear-eyed about its dangers—offers crucial guidance as we navigate the promises and perils of artificial intelligence. His work reminds us that technological progress without corresponding ethical advancement may lead not to utopia but to sophisticated forms of manipulation and control.
The GE-Chat Framework: Enhancing LLM Reliability Through Evidence-Based Responses
Large Language Models (LLMs) have become integral assistants in human decision-making processes, yet they come with a significant caveat: "LLMs can make mistakes. Be careful with any kind of important info." This warning underscores the reality that LLM outputs aren't always dependable, requiring users to manually evaluate their accuracy. The problem is compounded by hallucinated responses—incorrect information presented with convincing explanations—which erode user trust and complicate decision-making.
Introducing GE-Chat: A Solution to LLM Hallucinations
GE-Chat represents an innovative knowledge Graph Enhanced retrieval-augmented generation framework designed specifically to produce evidence-based responses. When users upload documents, the system creates a knowledge graph that forms the foundation of a retrieval-augmented agent, significantly enhancing the model's responses with information beyond its training corpus. This approach directly addresses the hallucination issue by grounding LLM outputs in factual evidence derived from user-provided documents.
The dangers of hallucinations in Large Language Models cannot be overstated, as they pose significant risks across multiple domains. These fabricated outputs—factually incorrect or entirely made-up responses—threaten scientific integrity, legal accuracy, and cybersecurity, with recent studies revealing disturbing and pervasive errors even among popular models. As of May 2025, these distortions continue to present serious risks of misinformation and potential exposure of confidential data, with experts noting that despite various mitigation techniques, no one has successfully eliminated hallucinations entirely. This persistent problem puts users at considerable risk, particularly in high-stakes environments where factual accuracy is paramount, making solutions like GE-Chat's evidence-based approach increasingly critical for socially responsible AI deployment.
The framework's sophistication lies in its multi-layered approach to evidence retrieval, leveraging Chain-of-Thought (CoT) logic generation, n-hop sub-graph searching, and entailment-based sentence generation. These mechanisms work in concert to identify precise evidence within free-form contexts, providing users with a reliable method to verify the sources behind an LLM's conclusions and assess their trustworthiness.
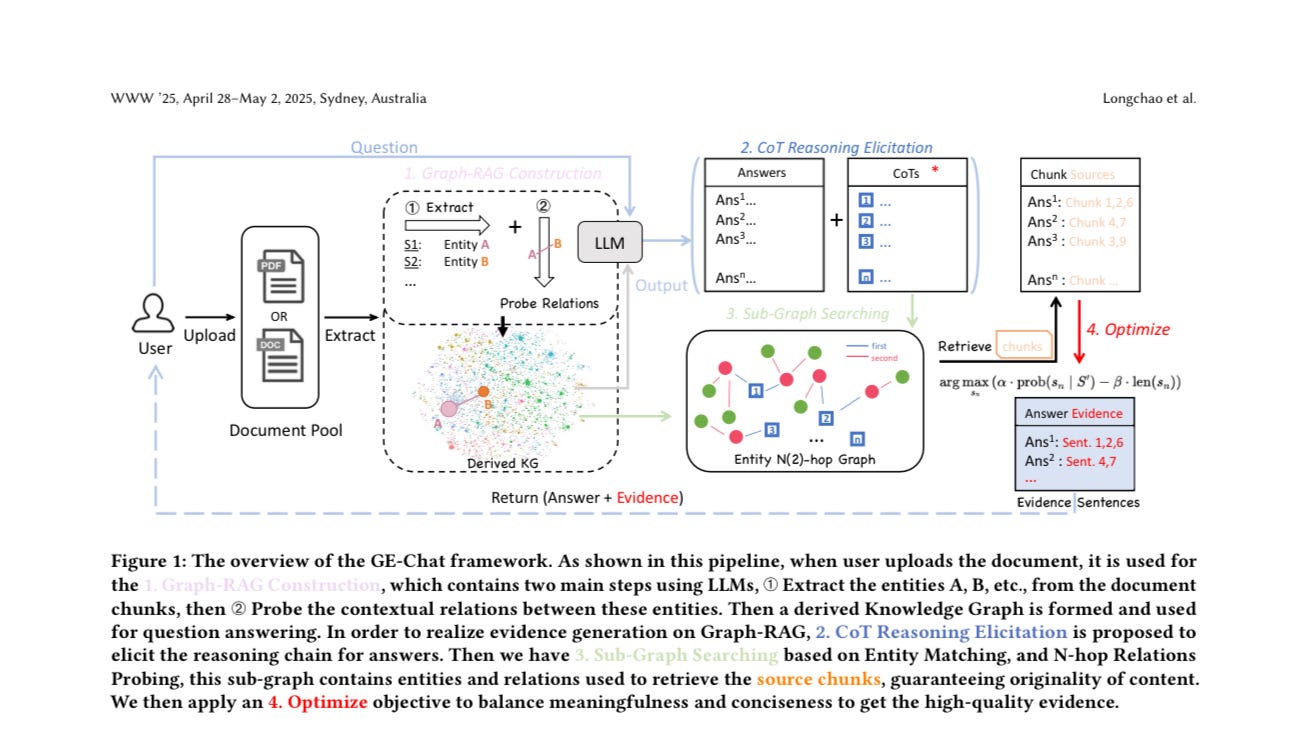
Figure 1 illustrates the overall architecture of the GE-Chat framework, depicting how the system processes user documents and generates responses. The flow involves four primary components:
Graph-RAG Construction: Retrieval-Augmented Generation (RAG) is a technique that enhances the output of large language models by referencing external knowledge sources before generating responses. In Graph-RAG Construction, when a user uploads a document, the system processes it by extracting entities from document chunks and investigating the relationships between these entities to construct a comprehensive knowledge graph. This knowledge graph serves as an authoritative foundation that the RAG system can query when responding to user questions, allowing the model to ground its answers in specific, relevant information rather than relying solely on its pre-trained parameters. By leveraging this structured representation of document knowledge, the system can provide evidence-based responses with greater precision and accuracy, effectively addressing common LLM challenges such as presenting outdated or false information. This approach combines the strengths of traditional information retrieval systems with generative AI capabilities, creating a more reliable and contextually aware question-answering system.
CoT Reasoning Elicitation: After constructing the knowledge graph, GE-Chat employs Chain-of-Thought reasoning to generate a logical sequence leading to answers. This transparent reasoning process allows users to understand how the model arrived at its conclusions.
Sub-Graph Searching: The system then searches for relevant subsets of the knowledge graph using entity matching and n-hop relations. This targeted approach ensures that retrieved evidence directly connects to claims in the generated responses, maintaining both relevance and originality.
Evidence Optimization: In its final stage, GE-Chat optimizes the presented evidence by striking a balance between meaningfulness and conciseness. The framework employs a specialized evaluation metric called Evidencescore that combines cosine similarity and conciseness to assess the quality of generated evidence.
🐴 Is Chain-of-Thought (CoT) Transparency the New Trojan Horse for Truly Transformative AI?

“We strive for the best we can attain within the scope the world allows.”
Technical Implementation
GE-Chat is a system designed to make large language models (LLMs) more reliable by not only generating answers, but also showing the evidence behind those answers. Imagine you’re asking a chatbot a question about a news article. Instead of just giving you a response, GE-Chat breaks down the article into smaller pieces, finds important people, places, or things (called entities), and then looks for how these entities are connected. This process is a bit like highlighting all the names and topics in a story and then drawing lines between them to show their relationships.
Technically, this involves three main steps. First, GE-Chat extracts entities from the text, which takes time based on how much text there is and how long each piece is. Next, it checks how these entities relate to each other, which gets more complex as the number of entities grows. Finally, it searches through a map of these relationships (a sub-graph) to find supporting evidence, typically looking just two steps away from each entity to keep things efficient. Most of the heavy lifting happens in the first two steps: finding the entities and figuring out their connections.
Sentence-Level Evidence Tracing: Breaking Open the Black Box?
The introduction of sentence-level evidence tracing in the GE-Chat framework offers a compelling glimpse into the reasoning process behind AI-generated content. By linking responses directly to specific sentences in original documentation, this feature appears to lift the veil on the opaque decision-making of large language models. Users can now trace model outputs back to concrete evidence, providing a sense of transparency and accountability that is often lacking in AI systems.
Yet, while this enhancement improves traceability, it does not fully demystify the inner workings of the AI’s reasoning. The cognitive pathways—the intricate, often nonlinear routes guiding the model’s preferences and conclusions—remain hidden within the complexities of machine learning architectures. In this sense, sentence-level tracing illuminates only the surface layer, leaving the deeper mechanisms of AI reasoning largely unexamined. This limitation raises questions about how much trust users can place in the model’s reliability and whether surface-level evidence is sufficient to challenge the deeply held convictions shaped by less transparent reasoning processes.
Approach to the GE-Chat Framework
The GE-Chat framework integrates several methodologies to enhance the response generation capabilities of large language models:
Graph-RAG Construction: The process begins with building a Retrieval-Augmented Generation (RAG) agent using a structured knowledge graph. This graph is constructed by extracting key entities and their relationships from uploaded documents, forming a robust informational foundation.
Chain-of-Thought (CoT) Reasoning Elicitation: Once the knowledge graph is in place, a CoT template is used to elicit logical reasoning chains. This ensures that generated answers reflect a structured, step-by-step reasoning process grounded in the user’s original data.
Efficient Sub-Graph Searching: The framework then conducts targeted sub-graph searches based on CoT outputs, efficiently mapping entities to supporting evidence within the knowledge graph. This focused retrieval enhances the precision and reliability of the model’s conclusions.
Figure 2 abstracts the sub-graph searching process within GE-Chat:
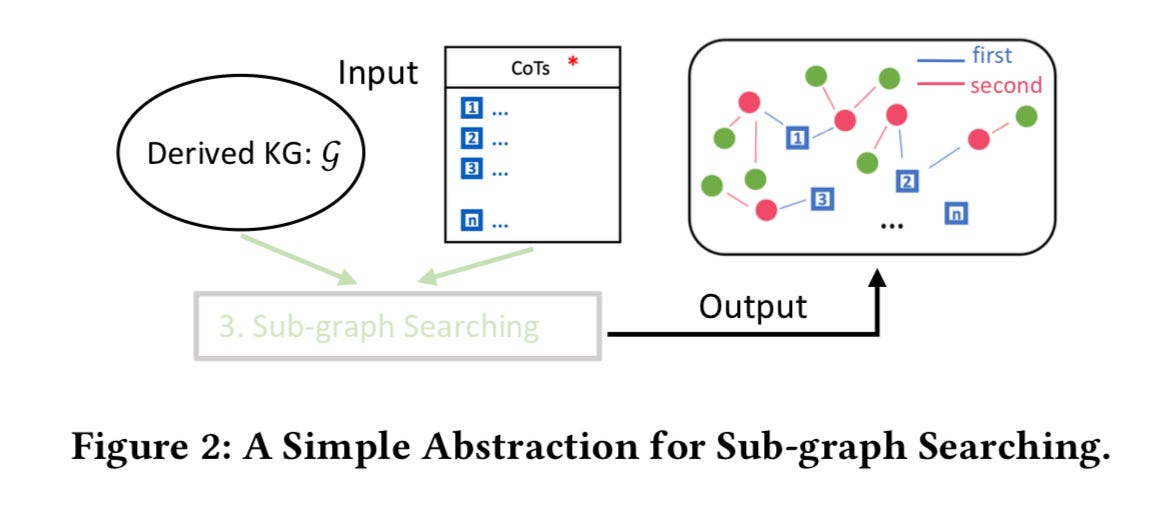
Input and Output Components: The diagram shows CoT reasoning results ((c_i)) as inputs—these are the logical steps derived during reasoning elicitation.
First and Second Hops: Blue boxes represent first-hop entities closely associated with CoT outputs, while green dots indicate second-hop relationships, revealing more distant but relevant connections in the knowledge graph.
This targeted approach avoids exhaustive document searches, anchoring responses in immediate and extended entity relationships. By linking outputs to concrete, sentence-level evidence, the framework enhances transparency and supports the model’s reliability—though it stops short of exposing the full cognitive machinery that underlies AI-generated reasoning.
The Ethics and Accountability of AI in Life-Altering Decisions
The central ethical challenge in the era of advanced AI is whether we should entrust significant, life-altering decisions to systems whose inner workings remain opaque. While modern frameworks like GE-Chat strive to address these concerns by enabling evidence tracing and enhancing accountability, the deeper questions about ethical reasoning and contextual wisdom persist. Simply providing citations or receipts does not automatically confer upon an AI the nuanced judgment required for complex, real-world scenarios. The stakes are especially high when errors in logic or reasoning could have profound consequences for individuals’ lives and livelihoods. As philosopher Bertrand Russell observed, while beliefs may arise from emotional necessity, it is our responsibility to rigorously challenge them with comprehensive evidence. Thus, the emergence of features like Google Gemini’s “receipts” and GE-Chat’s evidence tracing marks a significant step toward transparency, yet it remains to be seen whether these measures truly resolve the accountability issues or merely shift the burden of trust onto more traceable, but still imperfect, systems.
Experiment and Results: Validating the GE-Chat Framework
Section 3 of the report details the experimental setup and results that validate the effectiveness of the GE-Chat framework, focusing on the quality of evidence produced by Large Language Models (LLMs).
3.1 Experiment Setup
To address the scarcity of reliable evidence sources in prior research, the authors constructed a comprehensive dataset of 1,000 cases, spanning ten thematic categories such as Biology, Business, and Chemistry. Each case was further categorized along three dimensions:
Document Length: Short (<10 pages), Medium (10-100 pages), and Long (>100 pages).
Question Types: Synthesis (integrating multiple parts), Structure (examining organization), and Term Explanation (defining concepts).
Evidence Annotation: Each case included human-annotated answers and corresponding evidence sentences to ensure reliability.
The framework’s performance was evaluated using an “Evidence Score,” calculated via cosine similarity to assess the relevance of generated evidence against ground truth. This score quantifies the model’s ability to accurately connect answers to supporting data.
3.2 Experiment Results
The experiments revealed that baseline models varied in their effectiveness at direct evidence retrieval, with GPT4o performing best. However, many models struggled with conciseness, often generating excessive text. The GE-Chat framework significantly improved evidence-based response generation across models, enabling more efficient and accurate retrieval of evidence, as demonstrated by comparative metrics.
Figure 3 illustrates the user interaction with the GE-Chat framework:

Document Upload: Users upload relevant documents, such as PDFs.
Evidence Highlighting: The model processes the query in context, identifying and highlighting supporting evidence.
Output Generation: The system provides answers alongside the precise sentences from the document that substantiate them, ensuring traceability.
This workflow enhances transparency and reliability, allowing users to confidently reference the origins of the information provided. By making the process approachable and traceable, GE-Chat underscores the practical value of accountable AI in navigating complex data landscapes.
The pursuit of trustworthy AI represents a critical frontier in modern technology development. GE-Chat emerges as a significant advancement in this domain, offering a novel approach to evidence-based response generation that addresses fundamental challenges in LLM reliability.
Navigating the Frontier of Trustworthy AI
The GE-Chat framework stands as a promising innovation in our ongoing quest to enhance accuracy and accountability in artificial intelligence systems. By integrating knowledge graphs with retrieval-augmented generation methods, GE-Chat creates a robust foundation for evidence-based responses that significantly mitigate the risk of AI hallucinations. This approach transforms how we interact with language models, providing a transparent mechanism for tracing the origins of AI-generated information.
While representing a commendable effort toward more reliable AI systems, GE-Chat remains a work in progress that requires continued refinement. The framework's implementation of Chain-of-Thought logic generation, n-hop sub-graph searching, and entailment-based sentence generation creates a sophisticated system for accurate evidence retrieval. These technical innovations enable users to examine the resources behind an LLM's conclusions, facilitating informed judgment about response trustworthiness.
The computational architecture of GE-Chat involves three principal components: entity extraction, knowledge graph construction, and evidence-based response generation. This complexity analysis reveals both the sophistication of the approach and areas requiring optimization for broader deployment. Like a smart research assistant, GE-Chat not only retrieves information but comprehends the interconnections between knowledge fragments.
GE-Chat demonstrates remarkable versatility in improving performance across various model architectures. When users upload material documents, the system constructs a knowledge graph that enhances the agent's responses with information beyond its training corpus. This capability proves particularly valuable in contexts where precise information retrieval directly impacts decision-making processes.
The path forward demands vigilance, ethical scrutiny, and an unwavering commitment to transparency. Without these guiding principles, even promising frameworks like GE-Chat risk becoming transient advancements in a field characterized by rapid evolution and persistent challenges. By offering a user-friendly approach to evidence verification, GE-Chat contributes significantly to making AI systems more reliable and trustworthy.
As we navigate this critical juncture in AI development, we must balance technological innovation with ethical responsibility. The choices we make today will profoundly influence tomorrow's technologies, particularly in how they support human decision-making while maintaining accountability for the information they provide.
Conclusion
In conclusion, GE-Chat emerges as a revolutionary framework that addresses the fundamental challenges of accuracy and accountability in AI-generated responses. This knowledge Graph Enhanced retrieval-augmented generation framework represents a significant breakthrough in our collective effort to combat misinformation and hallucinations in large language models. By constructing comprehensive knowledge graphs from user-provided documents, extracting entities, and probing relations among them, GE-Chat creates a robust foundation for evidence-based responses that users can trust with confidence. The framework's sophisticated approach to evidence retrieval—combining Chain-of-Thought logic generation, n-hop sub-graph searching, and entailment-based sentence generation—provides unprecedented transparency in AI reasoning, allowing users to trace exactly how and why specific conclusions were reached.
The integrity of GE-Chat lies in its meticulous design that prioritizes both relevance and reliability. When processing user queries, the system doesn't merely generate plausible-sounding answers; it systematically searches for relevant subsets of the knowledge graph using entity matching and n-hop relations, ensuring that every claim is directly supported by concrete evidence. This evidence-first approach transforms how we interact with AI systems, shifting from blind trust to informed verification. The framework's sentence-level evidence tracing capability represents a significant step toward opening the "black box" of AI reasoning, providing users with clear pathways to verify the sources behind an AI's conclusions. By striking an optimal balance between meaningfulness and conciseness in its evidence presentation, GE-Chat delivers information that is both comprehensive and accessible, making complex AI reasoning transparent to users across various domains and expertise levels.
As we navigate increasingly complex information ecosystems, the trustworthiness of GE-Chat stands as its most valuable attribute for the Ethics & Data Governance for AI community. Unlike conventional AI systems that may present hallucinated information with convincing explanations, GE-Chat grounds every response in verifiable evidence derived directly from user-provided documents. This evidence-based approach directly addresses the erosion of trust that has plagued AI adoption in critical decision-making contexts. The framework's implementation of Graph-RAG construction creates a structured knowledge representation that serves as an authoritative foundation, allowing the system to provide precisely targeted information rather than relying solely on pre-trained parameters that may contain outdated or incorrect information. This commitment to factual accuracy makes GE-Chat an indispensable tool for professionals who require reliable, verifiable information to guide consequential decisions.
The GE-Chat framework represents not merely a technical achievement but a moral imperative for responsible AI development. In a world where misinformation spreads with unprecedented speed and AI systems increasingly influence critical aspects of human life, we cannot afford to deploy technologies that perpetuate falsehoods or unnecessarily obscure their reasoning processes. GE-Chat stands as a beacon of ethical AI design, demonstrating that technological sophistication and moral responsibility can advance in tandem. By providing transparent, evidence-based responses that users can verify and trust, this framework empowers the Ethics & Data Governance community to establish new standards for AI accountability. As we continue to integrate AI systems into our decision-making processes, frameworks like GE-Chat will prove indispensable in ensuring that these powerful technologies serve as reliable partners in our pursuit of truth, enhancing human judgment rather than undermining it through hallucinations or opaque reasoning. The future of trustworthy AI begins with evidence-based frameworks like GE-Chat, making it an essential cornerstone for building AI systems worthy of our confidence and trust!